
While they regularly deliver great results, great AI models are generally black boxes: it is not known exactly how they calculate their answers and many items are not made public. The BigScience project, in which a thousand researchers participate in a participatory and open scientific approach, is changing the situation with Bloom.
It is the largest fully open and transparently trained multilingual language model. This type of AI simultaneously learns the text generation model and the text representation model by repeatedly performing an initial task: predicting the next word of text whose beginning is known, in a way that makes keyboards “smart”. In addition to managing 46 languages, ranging from English to Basque, its character open flag It will help scientists from all walks of life explore how language models work to improve them. The BigScience project, initiated by Hugging Face, was supported by CNRS, GENCI and the Ministry of Higher Education and Scientific Research, making it possible to train Bloom on the “Jean Zay” machine, one of the most powerful supercomputers in Europe. Philippe Lavocate, Chairman and CEO of GENCI, announced:
“BigScience starts the world first and paves the way for further scientific discoveries. It has taken advantage of the resources of the Jean Zay convergent supercomputer, one of the most powerful computers in Europe, which was commissioned in 2019 in the wake of the Plan Artificial Intelligence for Humanity. Today, more than 1,000 research projects are working to mobilize its resources. Crucial to this success, the extension of Jan Zee’s work at the beginning of the year is the result of joint work between the Ministry of Higher Education and Research, the National Center for Scientific Research through the Institute for Development and Resources in Scientific Computing (IDRIS), and GENCI »
Language models are artificial intelligence whose first applications relate to texts in natural language: answers to questions, automatic sentence generation, “feeling” detection, automatic summarization and simplification or even machine translation. Most of the current models were generally designed by giants of new technologies, trained only with texts written in English and according to principles and methods that are difficult to reproduce in every detail. For example, it is not possible to know if the answer is the result of an arithmetic operation or whether the answer has already appeared in its learning databases, when the model answers a question.
The BigScience project was launched in the spring of 2021 by French-American artificial intelligence company Hugging Face, to tackle these problems by training a new model: Bloom. It learns from a large set of texts, using a simple principle, which consists in predicting the completion of sentences, word for word. Each prediction of the model is compared with the correct word, which makes it possible to adjust the internal parameters of the model. In Bloom’s case, learning is done by evaluating trillions of words, resulting in a model with 176 billion parameters. This learning took several months, and required hundreds of GPUs running in parallel, the equivalent of 5 million hours of computation. Such computing power can only be obtained on supercomputers like Jean Zay’s machine. Thomas Wolfe, co-founder and scientific director of the startup Hugging Face points out:
“The creation of Bloom’s model and the success of the research collaboration at BigScience shows that there is yet another way to create, study and share innovations in artificial intelligence, bringing together industrialists, academics, and associations around an international, interdisciplinary and innovative project. Open Access. I am pleased that Hugging Face was able to find support necessary in France for this unprecedented approach on a global scale.”
Bloom differs from other linguistic paradigms in that it is simultaneously trained in 46 languages, spread across sources as diverse as literature, scientific articles or sports reports and includes many languages that are rarely taken into account, particularly about two dozen African languages. The learning kit even contains computer code! All worth several million pounds. However, the greater the variety of approaches and sources, the greater the ability of the model to perform various tasks. The data is also not categorized according to their language because, paradoxically, Bloom learns best this way. Aggregating content in different languages allows powerful and effective learning of models for all the languages considered, and often yields better results than monolingual models. Another feature: Bloom’s architecture, list of data used and its learning history will be fully available at open flag, to facilitate the search for language models. Finally Bloom is distributed for free using a file Responsible licensewhich expressly prohibits malicious use of the form.
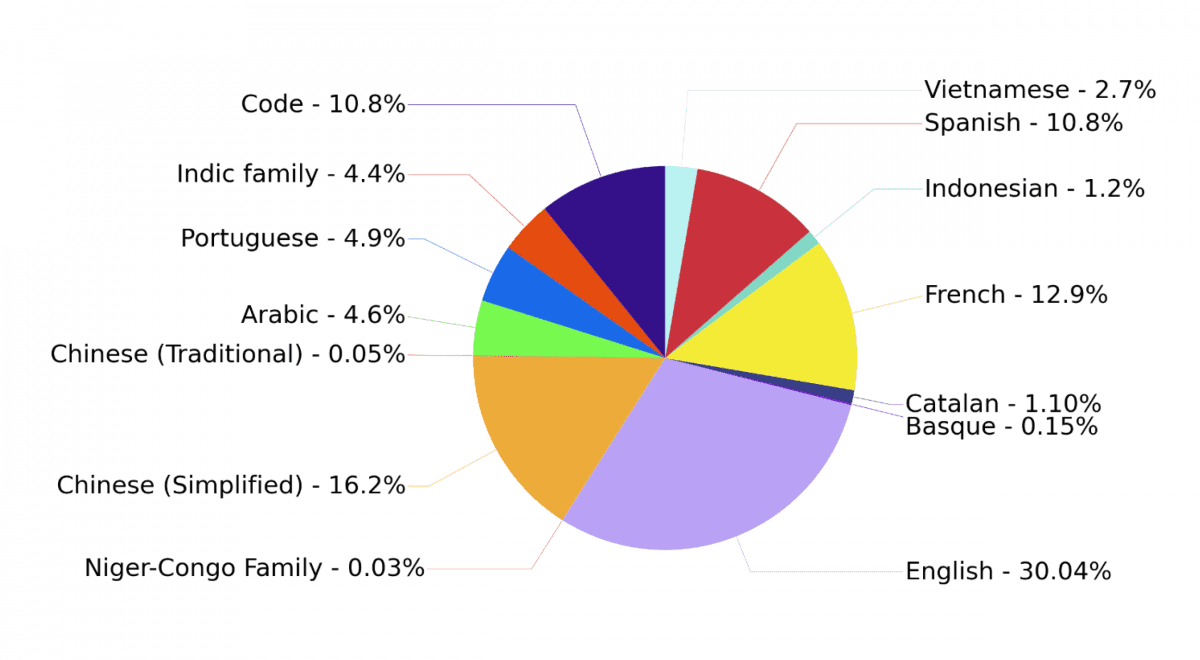
The “Indian family” covers about fifteen languages of the Indian subcontinent (Hindi, Tamil, Urdu, etc.) and the “Niger-Congo family” about twenty languages of sub-Saharan Africa (Swahili, Yoruba, Wolof, etc.). 10.8% of the data consisted of computer code, in 13 different languages.
Source: Hugging Face
Antoine Petit, President and CEO of the National Committee for Scientific Research adds:
We are delighted with this original public-private partnership, which demonstrates how the integration of skills and means – such as the power of the Jean Zay supercomputer – is necessary to meet such an important and modern challenge as research in artificial intelligence. Behind Scientific Advances, we salute the participation of the Idris crew who made this supercomputer training possible, and welcome the essential role that CNRS plays by mobilizing the entire ALP community. »

“Subtly charming problem solver. Extreme tv enthusiast. Web scholar. Evil beer expert. Music nerd. Food junkie.”

{kind=link}